在軟件工程實踐中,異常處理是確保系統可靠性和可維護性的關鍵組件。特別是對于Java開發,其內置的異常機制結合UML建模工具和軟件工程組織原則,可以顯著提升代碼質量和團隊協作效率。本文從異常處理的概念出發,探討其在UML設計中的表示方法,并結合軟件工程組織的最佳實踐,闡述如何實現有效的異常管理策略。
一、Java異常處理概述
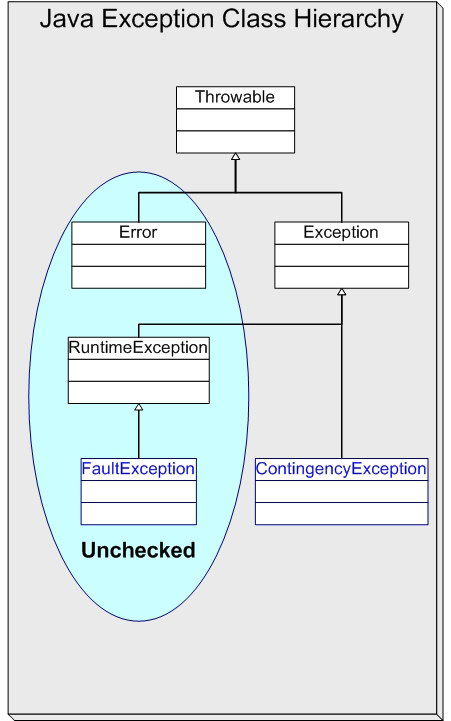
Java的異常處理基于try-catch-finally結構,并區分受檢異常(Checked Exception)和未受檢異常(Unchecked Exception)。受檢異常強制開發者處理潛在錯誤,如IOException;未受檢異常(如NullPointerException)通常表示編程錯誤,無需顯式捕獲。有效的異常處理應遵循以下原則:
- 精確捕獲:僅捕獲可處理的異常,避免籠統的catch(Exception e)。
- 異常鏈:使用帶原因的異常構造,保留原始異常信息。
- 資源管理:利用try-with-resources語句自動釋放資源,減少內存泄漏風險。
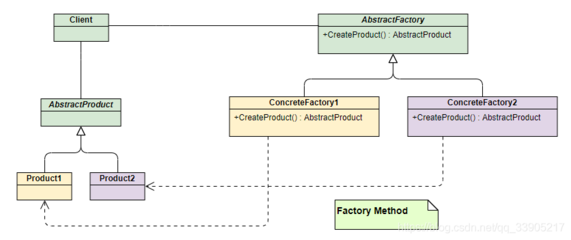
二、UML中的異常建模
統一建模語言(UML)為軟件設計提供了可視化工具,異常處理在UML中可通過以下方式表示:
- 序列圖:展示對象間交互時可能拋出的異常,使用異步消息或交互片段(如alt組合片段)表示異常流。
- 類圖:定義自定義異常類,通過繼承關系(如擴展Exception類)展示異常層次結構。
- 用例圖:在擴展關系中標注異常場景,幫助識別系統邊界外的錯誤條件。
通過UML建模,團隊能在設計階段預見異常情況,減少后期調試成本。
三、軟件工程組織中的異常管理策略
在軟件工程組織中,異常處理不僅是技術問題,更涉及流程和協作:
- 標準化異常庫:建立組織級的異常類庫,統一錯誤代碼和消息格式,便于跨團隊理解。
- 代碼審查集成:在代碼審查過程中檢查異常處理邏輯,確保符合組織規范。
- 文檔化異常策略:使用Confluence或Wiki記錄異常處理指南,包括何時使用受檢/未受檢異常。
- 測試驅動開發(TDD):編寫單元測試覆蓋異常路徑,結合JUnit或TestNG驗證異常拋出。
- 監控與日志:集成Log4j或SLF4J記錄異常,并利用APM工具(如New Relic)實時監控生產環境異常。
四、案例:電商系統中的異常處理
以電商系統為例,用戶支付時可能遇到支付網關異常(受檢異常)或庫存不足異常(自定義未受檢異常)。在UML序列圖中,支付服務對象可向控制器拋出異常,觸發回滾流程;在組織層面,開發團隊需定義支付異常的子類,并在運維手冊中指定告警閾值。通過結合Java異常機制、UML建模和組織流程,系統可實現高可用性和快速故障恢復。
五、總結
有效的Java異常處理需要技術設計與工程管理的深度融合。UML建模幫助可視化異常流,而軟件工程組織則通過標準化和協作確保一致性。未來,隨著微服務和云原生架構的普及,異常處理將更注重分布式追蹤和自動化響應,但核心原則——及早發現、精確處理、全面文檔化——仍將是軟件質量的基石。